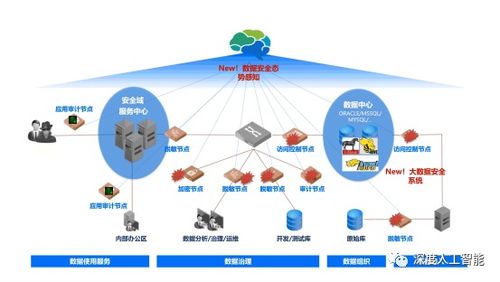
在當今信息爆炸的時代,數據處理已成為各行各業不可或缺的核心技能。Python憑借其簡潔的語法、強大的生態系統和豐富的庫支持,成為數據科學和數據處理領域的首選語言。無論是數據清洗、轉換、分析還是可視化,Python都能提供高效、靈活的解決方案。
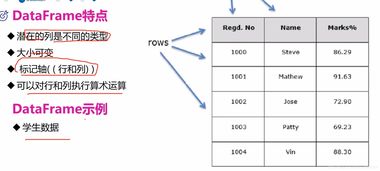
Python處理數據的基石在于其強大的庫。NumPy提供了高性能的多維數組對象和數學函數,是科學計算的基礎。Pandas則構建于NumPy之上,提供了DataFrame和Series等數據結構,使得數據清洗、篩選、聚合和轉換變得異常簡單。對于大型數據集,Pandas可以高效處理,而結合Dask等庫,甚至可以擴展到分布式計算環境。
數據清洗是數據處理的第一步,也是至關重要的一步。現實世界的數據往往存在缺失值、異常值、重復記錄等問題。Pandas提供了豐富的方法來處理這些挑戰。例如,使用dropna()或fillna()處理缺失值,通過drop_duplicates()去除重復行,利用條件篩選識別和修正異常值。字符串處理庫如re(正則表達式)和Pandas的字符串方法可以幫助清洗和標準化文本數據。
數據轉換與整合同樣重要。Pandas的merge()和concat()函數能夠輕松合并多個數據集,而groupby()操作則支持按特定維度分組并進行聚合計算(如求和、均值、計數等)。對于時間序列數據,Pandas提供了強大的時間處理功能,包括日期解析、重采樣、滑動窗口計算等。
在數據分析階段,Python的統計和機器學習庫大顯身手。SciPy和StatsModels支持高級統計分析,而Scikit-learn則提供了完整的機器學習工具鏈,涵蓋分類、回歸、聚類等多種算法。通過Matplotlib、Seaborn和Plotly等可視化庫,可以將分析結果以圖表形式直觀呈現,幫助洞察數據背后的規律和趨勢。
數據處理流程的自動化是提升效率的關鍵。結合Jupyter Notebook進行交互式開發,或使用腳本和自動化工具(如Airflow)構建數據處理管道,可以實現從數據采集、清洗、分析到報告生成的全流程自動化。
Python以其全面的庫支持和活躍的社區,為數據處理提供了從入門到精通的完整路徑。掌握Python數據處理技能,不僅能提升工作效率,更能為數據驅動的決策提供堅實支持。無論是初學者還是有經驗的開發者,都可以在Python的生態中找到適合自己的工具和方法,解鎖數據的無限價值。